
From Twilio Webhooks to LiveKit Agents: How a Client's Insistence Led to a Better Architecture
"You were right. What do we do next?" How a client insisted on the wrong architecture — and why letting him was the right call

There are calls you remember.
This was one of them.
A few weeks ago, a client called and said the sentence I’d been expecting since the project started: “You were right. What do we do next?”
To explain why that mattered, I need to start from the beginning.
How it started
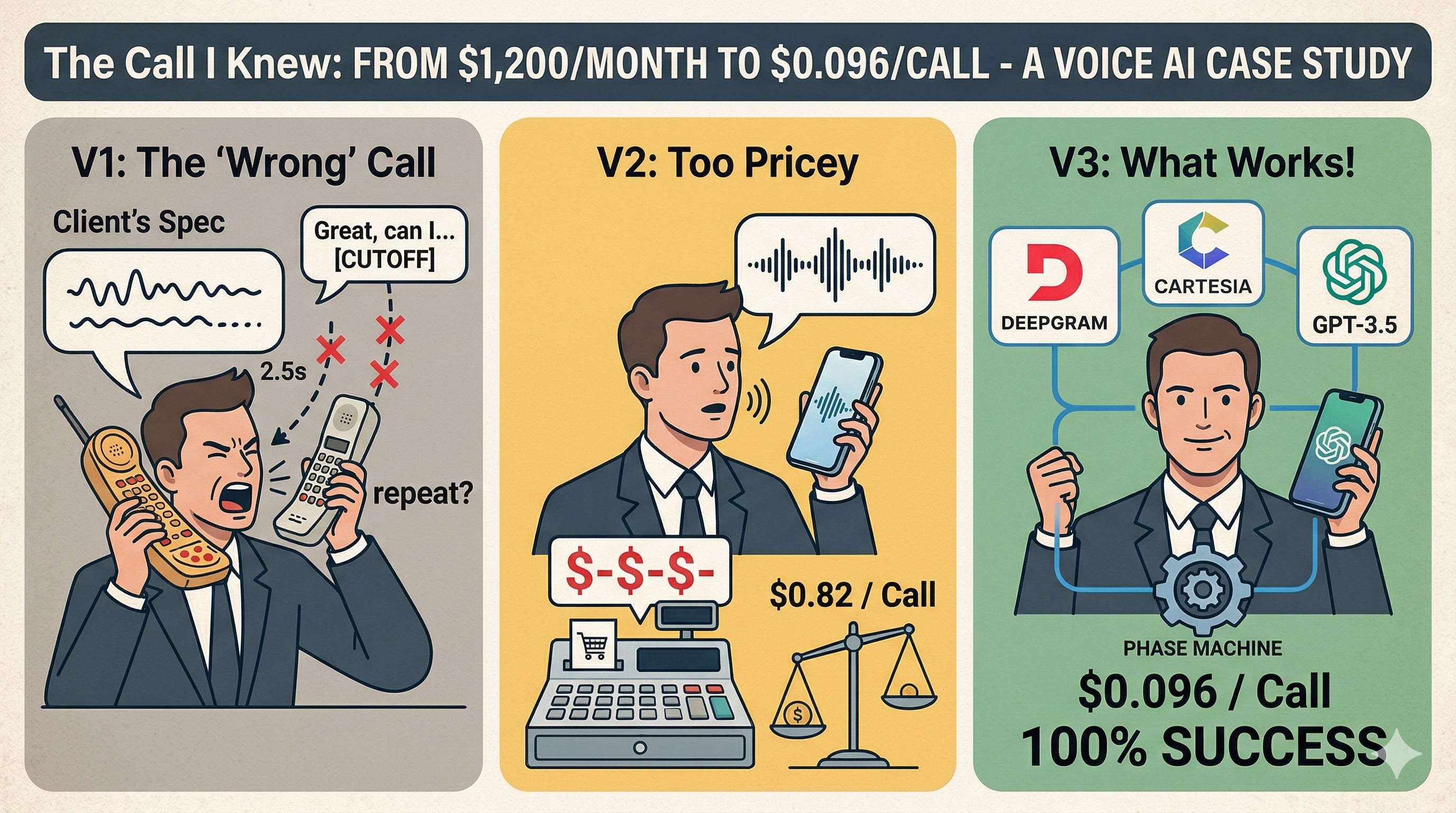
The client came with a specific ask: build a phone ordering AI for a pizza restaurant in New Jersey. Forty to sixty calls every evening. The owner was answering the phone himself instead of running the kitchen. Orders were getting lost during peak hours.
The technical spec was clear: Twilio Voice API, webhooks, Node.js. Standard stack. He’d seen similar setups before and knew what he wanted.
I had experience with this type of system. I told him upfront: webhook architecture introduces 1.5 to 2 seconds of latency per conversational turn. In a chat interface, that’s manageable. On a phone call, it feels like a dropped line. I recommended a streaming approach instead.
He listened and said: I understand your reasoning, but I want to see it for myself. Build it the way I’m asking.
The first version: exactly what he asked for
I could have pushed back harder. Instead I made a different call: if he needs to see it to believe it, let him see it. That’s more honest than winning an argument by authority.
I built the webhook pipeline exactly to spec. Twilio captures the call, sends audio to our server, Deepgram transcribes it, GPT generates a response, Amazon Polly converts it back to speech, TwiML returns it to the customer. Six services in sequence.
We ran the test calls. Here’s what a typical exchange looked like:
“I’d like two cheese pizzas.”
[1.9 seconds of silence]
“Great, two cheese pizzas. Anything else?”
“Yeah, and also—” [system cuts off mid-sentence]
[2.1 seconds of silence]
“I’m sorry, I didn’t catch that. Could you repeat?”
Pass rate: 68%. One in three orders had errors.
I sent him the call recordings and the numbers. No commentary.
“You were right. What do we do next?”
That’s the call I’ll remember.
Not because I’d been right. Because of what it changed. From that point on, the client stopped issuing technical directives and started asking questions. We started working like actual partners.
I suggested trying the OpenAI Realtime API — a bidirectional WebSocket that handles speech recognition, language model, and voice synthesis in a single streaming pipeline. No sequential processing. Natural barge-in support. The kind of UX that actually feels like a conversation.
The quality was immediately better. 96.6% order completion rate, zero barge-in issues, calls thirty seconds shorter. He listened to the test recordings and was happy.
Then I looked at the bill. $0.82 per call.
At fifty calls a day, that’s $1,230 a month — more expensive than hiring a part-time employee. His target was $0.08 to $0.12 per call.
I called him again. “Quality is great. Cost is seven to ten times your budget. Give me more time — I want to try a third approach.”
This time he said simply: “Okay. Do what you think is right.”
The third version: what actually works
The insight was straightforward: the Realtime API sells convenience — one pipeline, one API key. You’re paying for the integration, not the raw compute. If you unbundle the pipeline and pick the best provider for each component separately, you can get the same quality for significantly less.
I rebuilt the system on LiveKit: Deepgram for speech recognition with custom keyterms boosting the restaurant’s specific menu vocabulary, GPT-5.4-mini for the language model (not a reasoning model — voice AI needs speed, not deliberation), Cartesia for speech synthesis with low latency and emotion control.
The most important architectural decision: take flow control away from the LLM entirely.
Earlier versions let the model manage the conversation. Even with careful prompting, it would occasionally skip confirmation steps, ask for the customer’s name before confirming the order, or once add an item to the cart that didn’t exist on the menu. A prompt is an instruction. It’s not a contract.
The production system uses a deterministic phase machine for flow control — a pure function that takes the current order state and returns the current phase and what transitions are allowed. The model’s job is limited to one thing: understand what the customer said and call the right tool. Everything else is handled by code that’s testable and predictable.
Result: $0.096 per call. 100% order completion on the latest test rounds. Calls averaging 55 seconds instead of over two minutes.
What I took away from this
Sometimes the best way to move a client forward is to let them arrive at the conclusion themselves. Not because you need the satisfaction of being right — but because the experience changes something that an argument can’t.
After that first version, the client became an ally. We stopped spending energy on disagreement and put it into the work instead.
It cost a few weeks and three complete architecture rewrites. But it ended with a system in production, a client who trusts the process, and a working relationship that’s genuinely collaborative.
I’ve documented the full technical architecture — cost breakdown, component selection rationale, the phase machine design — in my guide to building AI systems in production. If you’re working on something similar, it’s here: [Gumroad]